R apply家族函数 详解
要点: 要想追求速度,就要尽量避免在R中使用for循环,而是用向量化的思维处理数据框。[R In Action,2nd: mainly in Chapter5.3]
- apply家族函数概述
- apply(X, MARGIN, FUN, ...)
- 循环迭代 lapply, 对list使用fn,并返回list (sapply返回矩阵)
- tapply: table(), by()
- rapply, 递归版本的lapply,只处理list类型数据
- eapply, 对环境内的所有变量批量(开发R包用)//todo
- aggregate(df, by=list(vect1, vect2), FUN=)
- Sweep out Array Summaries
在使用R时,要尽量用array的方式思考,避免for循环。
重点: base包中split – apply – combine 数据处理模式。
R是一种面向数组(array-oriented)的语法,它更像数学,方便科学家将数学公式转化为R代码。apply族功能强大,实用,可以代替很多循环语句。因为向量在R中在底层用C语言优化过,运行更快,性能更好,在使用R时,要尽量用array的方式思考,避免for、while循环语句,特别是数据量大的时候。
apply函数族是R语言中数据处理的一组核心函数,通过使用apply函数,我们可以实现对数据的循环、分组、过滤、类型控制等操作。但是,由于在R语言中apply函数与其他语言循环体的处理思路是完全不一样的,所以apply函数族一直是使用者玩不转的一类核心函数。很多R语言新手,写了很多的for循环代码,也不愿意多花点时间把apply函数的使用方法了解清楚,最后把R代码写的跟C似的,只会写for的R程序员的代码是效率低下的,是被鄙视的。
不用循环怎么实现迭代呢?这就需要用到 apply 函数族。它不是一个函数,而是一族功能类似的函数。
apply族函数是高效能计算的运算向量化(Vectorization)实现方法之一。常用的向量操作就是apply的家族函数:apply, sapply, tapply, mapply, lapply, rapply, vapply, eapply等。
apply 家族函数特别注意三点: 功能,输入,输出。
分组计算
tapply: 参数 vector, 返回 vector
apply: 参数 list, data.frame, array, 返回 vector, matrix
循环迭代
lapply:
简化版 sapply:
可检查返回值类型 vapply: 参数 list, data.frame, 返回 vector, matrix
递归版 rapply: 参数 list,返回 list
多参数计算
mapply: 参数为 个数不限的vector,返回 vector, matrix
遍历环境空间
eapply: 参数 environment, 返回 list
X是数据框,margin只能是1(by row)或2(by column), fun是要应用的方程。
用apply可以很方便地按行列求和/平均,其结果与colMeans,colSums,rowMeans,rowSums是一样的。
#例1:比如,对一个数据框每一列求平均数,下面就要用到apply做循环了。
x=data.frame(cell1=c(10,20,15,26,30),cell2=c(100,180,160,179,40))
rownames(x)=paste0("gene",1:5)
x
# cell1 cell2
# gene1 10 100
# gene2 20 180
# gene3 15 160
# gene4 26 179
# gene5 30 40
apply(x,2,mean) #按列计算均值
#cell1 cell2
# 20.2 131.8
apply(x,1,mean) #按行
#gene1 gene2 gene3 gene4 gene5
# 55.0 100.0 87.5 102.5 35.0
## 最后的函数可以使用
apply(x,1,sum) #求和
apply(x,1,median) #中位数
apply(x,1,sd) #标准差,方差的开方
apply(x,1,var) #方差
apply(x,1,max) #最大值
apply(x,1,min) #最小值
apply(x,1,fivenum) #数据的分位数
apply(x,1,cumsum) #累加
t(apply(x,1,function(x)x**2)) #每个元素分别求平方
## apply的返回值是 named number,可以通过自定义函数变为数据框
## 实现了添加列名、按值排序、输出行列、前几行;
getDF_fromNamesXX=function(namedXX,debug=F){
rs=data.frame(
name=names(namedXX),
value=as.numeric(namedXX)
)
row.names(rs)=rs$name
rs=rs[order(-rs$value),]
if(debug==T){
print(dim(rs))
print(head(rs))
}
return(rs)
}
getDF_fromNamesXX(apply(x,1,mean))
# name value
# gene4 gene4 102.5
# gene2 gene2 100.0
# gene3 gene3 87.5
# gene1 gene1 55.0
# gene5 gene5 35.0
如果现有函数无法满足需要,还可以自定义函数。
# 例2: 按列进行标准化,相当于求cpm
> cpm=apply(x,2,function(x){x/sum(x)*1e6})
> cpm
cell1 cell2
gene1 99009.9 151745.07
gene2 198019.8 273141.12
gene3 148514.9 242792.11
gene4 257425.7 271623.67
gene5 297029.7 60698.03
## 再求log2(cpm+1)
> log2cpm=log2(cpm+1)
> log2cpm
cell1 cell2
gene1 16.59530 17.21130
gene2 17.59529 18.05929
gene3 17.18026 17.88937
gene4 17.97380 18.05126
gene5 18.18025 15.88939
## 写成一个函数
# 可以接受文件路径,或者counts矩阵
getNormalizedCts = function ( ctsPath, filename=T ) {
if(filename==T){
cts = read.table ( ctsPath , header = T , as.is = T )
}else{
cts=ctsPath
}
apply ( cts , 2 , function ( x ) { log2 ( ( 10^6 ) * x / sum ( x ) + 1 ) })
}
getNormalizedCts(x,F)
# cell1 cell2
# gene1 16.59530 17.21130
# gene2 17.59529 18.05929
# gene3 17.18026 17.88937
# gene4 17.97380 18.05126
# gene5 18.18025 15.88939
## 更综合的例子
# 按列,求香农指数: -p*log(p)的累加和
getEntropy = function ( cts ) {
#print(cts)
prop=apply(cts, 2, function(x){ x/sum(x)})
#print(prop)
entropy = apply( -prop*log10(prop+1e-100), 2, sum )
#
df=data.frame(
cid=names(entropy),
entropy=as.numeric(entropy)
)
row.names(df)=df$cid
#
return(df)
}
> getEntropy(x)
cid entropy
cell1 cell1 0.6700153
cell2 cell2 0.6550746
我们可以在apply中加入条件判断。
# 造一个需求: 对于每个基因,cell1/cell2 大于0.1,则返回cell1,否则返回cell2的表达量
# 方法1: if(){}else{}
apply(x, 1, function(x){
if( x[1]/x[2] >0.1){
return(x[1])
}else{
return(x[2])
}
})
#Tips: 自定义函数中,输入变量是原数据框的一行或一列,如果要对其中一个元素操作,要加下标(R下标从1开始)。
# 方法2: ifelse(a>b, x, y)
apply(x, 1, function(x){
ifelse( x[1]/x[2] >0.1, x[1], x[2])
})
# gene1 gene2 gene3 gene4 gene5
# 100 20 160 26 30
lapply returns a list of the same length as X, each element of which is the result of applying FUN to the corresponding element of X.
lapply函数是一个最基础循环操作函数之一,用来对list、data.frame数据集进行循环,并返回和X长度同样的list结构作为结果集,通过lapply的开头的第一个字母’l’就可以判断返回结果集的类型。
lapply就可以很方便地把list数据集进行循环操作,还可以用data.frame数据集按列进行循环,但如果传入的数据集是一个向量或矩阵对象,那么直接使用lapply就不能达到想要的效果了。
函数定义:lapply(X, FUN, ...)
参数列表:
X:list、data.frame数据
FUN: 自定义的调用函数
…: 更多参数,可选
lapply(mtcars, sum) #计算每一列的总和
# $mpg
# [1] 642.9
#
# $cyl
# [1] 198
# ...
#因为数据框本质上也是列list
mtcars[[1]] #第一列
# [1] 21.0 21.0 22.8 21.4 ...
split(1:10, 1:10), it means split the number 1 to 10 into 10 groups.
f: 函数,一个factor或者list(如果list中元素交互作用于分组中),以此为规则将x分组
drop: 逻辑值,如果f中的某一个level没有用上则被弃用
#例1: 把1-10分成2组,则一组是奇数,一组是偶数
> split(1:10, 1:2)
$`1`
[1] 1 3 5 7 9
$`2`
[1] 2 4 6 8 10
#例2: 按照f拆分x: split(x, f, drop = FALSE, ...)
d = data.frame(gender=c("M","M","F","M","F","F"),
age=c(47,59,21,32,33,24),
income=c(55000,88000,32450,76500,123000,45650),
over25=rep(c(1,1,0), times=2))
d
# gender age income over25
#1 M 47 55000 1
#2 M 59 88000 1
#3 F 21 32450 0
#4 M 32 76500 1
#5 F 33 123000 1
#6 F 24 45650 0
grps=split(d$income, list(d$gender,d$over25)) #将income按照gender、over25分组,2*2=4组
grps
# $F.0
# [1] 32450 45650
#
# $M.0
# numeric(0)
#
# $F.1
# [1] 123000
#
# $M.1
# [1] 55000 88000 76500
lapply(grps, mean) #对list分别求平均
# $F.0
# [1] 39050
#
# $M.0
# [1] NaN
#
# $F.1
# [1] 123000
#
# $M.1
# [1] 73166.67
# 例3: 年少多金组: 超过平均工资的一半,且低于25岁。组外组内。
split(d$income, d$income>0.5*mean(d$income) & d$age<25)
# $`FALSE`
# [1] 55000 88000 32450 76500 123000
#
# $`TRUE`
# [1] 45650
sapply(data, fn) 还可以用来画图,批量画几个panel。
sapply 函数是一个简化版的lapply,sapply增加了2个参数simplify和USE.NAMES,
主要就是让输出看起来更友好,返回值为向量,而不是list对象。
函数定义:sapply(X, FUN, ..., simplify=TRUE, USE.NAMES = TRUE)
参数列表:
X:数组、矩阵、数据框
FUN: 自定义的调用函数
…: 更多参数,可选
simplify: 是否数组化,当值array时,输出结果按数组进行分组
USE.NAMES: 如果X为字符串,TRUE设置字符串为数据名,FALSE不设置
simplify=F:返回值的类型是list,此时与lapply完全相同。
想要返回的结果是一个向量或矩阵,设置
simplify=T(默认值):返回值的类型由计算结果定,如果函数返回值长度为1,则sapply将list简化为vector;
如果返回的列表中每个元素的长度都大于1且长度相同,那么sapply将其简化为一个矩阵。
# 例1: 对数据框分组,求分组后每组的列平均值
## 对数据框的分组
head(airquality)
# Ozone Solar.R Wind Temp Month Day
# 1 41 190 7.4 67 5 1
# 2 36 118 8.0 72 5 2
#按月份分组
airByMonth=split(airquality, airquality$Month) #airByMonth是一个list,每个元素是一个df
sapply(airByMonth, dim) #看每个分组的行列数
# 5 6 7 8 9 #月份
#[1,] 31 30 31 31 30 #行数
#[2,] 6 6 6 6 6 #列数
# 按月,求列的平均值 (apply家族函数的嵌套)
lapply(airByMonth,
function(x){ #传入的参数是lapply输出的,是list中的每个元素,就是每个月份的数据框
#apply(x,2,mean) #对这个数据框按列求平均数
#去掉na再求平均值:na.rm=T
apply(x,2,function(x){mean(x, na.rm=T)})
}
)
# $`5`
# Ozone Solar.R Wind Temp Month Day
# 23.61538 181.29630 11.62258 65.54839 5.00000 16.00000
#
# $`6`
# Ozone Solar.R Wind Temp Month Day
# 29.44444 190.16667 10.26667 79.10000 6.00000 15.50000
# lapply返回的是列表,如果想要表格形式
sapply(airByMonth, function(x){ apply(x,2,function(x){mean(x, na.rm=T)})} )
#或 求列mean更简短的函数
sapply(airByMonth, function(x){colMeans(x, na.rm=T)})
# 5 6 7 8 9
# Ozone 23.61538 29.44444 59.115385 59.961538 31.44828
# Solar.R 181.29630 190.16667 216.483871 171.857143 167.43333
# Wind 11.62258 10.26667 8.941935 8.793548 10.18000
# Temp 65.54839 79.10000 83.903226 83.967742 76.90000
# Month 5.00000 6.00000 7.000000 8.000000 9.00000
# Day 16.00000 15.50000 16.000000 16.000000 15.50000
sapply(airByMonth, function(x){colMeans(x)}) #不加na.rm=T则结果中有NA
# 5 6 7 8 9
# Ozone NA NA NA NA NA
# Solar.R NA 190.16667 216.483871 NA 167.4333
# Wind 11.62258 10.26667 8.941935 8.793548 10.1800
# Temp 65.54839 79.10000 83.903226 83.967742 76.9000
# Month 5.00000 6.00000 7.000000 8.000000 9.0000
# Day 16.00000 15.50000 16.000000 16.000000 15.5000
求鸢尾花每个亚类中4个指标的平均值: 强大的 do.call() + lapply()
方法1: 使用 sapply+apply 实现:
sapply( split(iris[, 1:4], iris$Species), function(x){
apply(x, 2, mean)
} )
输出:
# setosa versicolor virginica
# Sepal.Length 5.006 5.936 6.588
# Sepal.Width 3.428 2.770 2.974
# Petal.Length 1.462 4.260 5.552
# Petal.Width 0.246 1.326 2.026
方法2: 使用 do.call + lapply 实现:do.call() 需要一个list作为输入,而lapply()正好返回一个list。
do.call(rbind, lapply(
split(iris[,1:4], iris[,5]),
function(x){
colMeans(x)
}
))
输出:
# Sepal.Length Sepal.Width Petal.Length Petal.Width
# setosa 5.006 3.428 1.462 0.246
# versicolor 5.936 2.770 4.260 1.326
# virginica 6.588 2.974 5.552 2.026
方法3: 使用 apply + tapply 实现,输出同2
apply(iris[,1:4], 2, function(x){
tapply(x, iris$Species, mean)
})
方法4: 使用 do.call + by 实现,输出同2
do.call(rbind, by(iris[,1:4], iris$Species, FUN = colMeans))
方法5: 使用 aggregate,结果同2,但是多了第一列
aggregate(iris[,1:4], by=list(iris$Species), function(x){
mean(x)
})
切片矢量
我们可以使用lapply()或sapply()互换来切片数据框。
# 筛选高于平均值的值
below_ave = function(x) {
ave = mean(x)
return(x[x > ave])
}
dt=iris[, 1:4]
dt_s = sapply(dt, below_ave)
dt_l = lapply(dt, below_ave)
identical(dt_s, dt_l)
# [1] TRUE
使用sapply(data, fn)分面
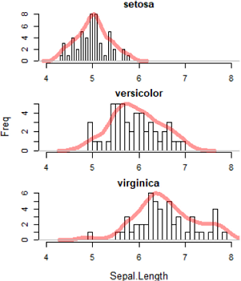
# 例: 3行1列, hist+density
par(mfrow = c(3,1), mar = c(2,1,2,1), oma = c(2,3,0,0))
sapply(levels(iris$Species), function(f) {
hist(iris$Sepal.Length[iris$Species == f], main = f, xlab = "", n=25, xlim=c(4,8) )
par(new=T)
plot(density(iris$Sepal.Length[iris$Species == f], n=50), xlim=c(4,8),
lwd=5,col='#FF000066', ann=F, axes=F )
#lines(density(iris$Sepal.Length[iris$Species==f], n=50), xlim=c(4,8), col='green')
})
mtext(side = 1, outer = T, line = 1, "Sepal.Length", cex = 0.8) #x标签
mtext(side = 2, outer = T, line = 2, "Freq", cex = 0.8) #y标签
vapply类似于sapply,提供了FUN.VALUE参数,用来检查返回值的类型,这样可以让程序更健壮。同时还可以重命名返回值的行名。
sapply是lapply的友好版本,但可预测性不好。如果是大规模的数据处理,后续的类型判断工作会很麻烦而且很费时。vapply增加的FUN.VALUE参数可以直接对返回值类型进行检查,这样的好处是不仅运算速度快,而且程序运算更安全(因为结果可控)。
函数定义:vapply(X, FUN, FUN.VALUE, ..., USE.NAMES = TRUE)
参数列表:
X:数组、矩阵、数据框
FUN: 自定义的调用函数
FUN.VALUE: 定义返回值的行名 row.names = 数据类型,等号左边可以省略,右侧的则必须有。
…: 更多参数,可选
USE.NAMES: 如果X为字符串,TRUE设置字符串为数据名,FALSE不设置
通过使用vapply可以直接设置返回值的行名,这样子做其实可以节省一行的代码,让代码看起来更顺畅,当然如果不愿意多记一个函数,那么也可以直接忽略它,只用sapply就够了。
比如,对数据框的列数据进行累计求和,并对每一行设置行名row.names
例1:df=mtcars[1:4,1:3];df
# mpg cyl disp
# Mazda RX4 21.0 6 160
# Mazda RX4 Wag 21.0 6 160
# Datsun 710 22.8 4 108
# Hornet 4 Drive 21.4 6 258
sapply(df,cumsum) #竖着累加
# mpg cyl disp
# [1,] 21.0 6 160
# [2,] 42.0 12 320
# [3,] 64.8 16 428
# [4,] 86.2 22 686
vapply(df,cumsum,
# 添加列名,必须是这种带等号的,左边是列名,右边是类型
# 左边的列名可以省略,但是右边的类型名字必须有。
FUN.VALUE=c('a'=0,'b'=0,'c'=0,'d'=0))
# mpg cyl disp
# a 21.0 6 160
# b 42.0 12 320
# c 64.8 16 428
# d 86.2 22 686
#或者只指定返回值类型
vapply(df,cumsum, rep(0,4))
# mpg cyl disp
# [1,] 21.0 6 160
# [2,] 42.0 12 320
# [3,] 64.8 16 428
# [4,] 86.2 22 686
例2: vapply比sapply安全?! 是因为 vapply 强制对返回值做简单的类型校验。
#按月份分组
airByMonth=split(airquality, airquality$Month) #airByMonth是一个list,每个月份是一个df
sapply(airByMonth, function(x){colMeans(x, na.rm=T)})
# 5 6 7 8 9
# Ozone 23.61538 29.44444 59.115385 59.961538 31.44828
# Solar.R 181.29630 190.16667 216.483871 171.857143 167.43333
# Wind 11.62258 10.26667 8.941935 8.793548 10.18000
# Temp 65.54839 79.10000 83.903226 83.967742 76.90000
# Month 5.00000 6.00000 7.000000 8.000000 9.00000
# Day 16.00000 15.50000 16.000000 16.000000 15.50000
## 注意: FUN函数获得的结果和 FUN.VALUE 设置的不一致(长度和类型)都会出错
# 可以根据vapply函数的这一功能,使用FUN.VALUE参数对数据进行批量检测。
# 报错:第二个函数返回值【类型】不符合第三个参数的设定
vapply(airByMonth, function(x){colMeans(x, na.rm=T)},
FUN.VALUE = seq(1,6) )
#报错: values must be type 'integer',
#but FUN(X[[1]]) result is type 'double'
# 但是改为 rep(1,6) 就不报错了,所以说 vapply 只进行了有限的返回值校验。
> vapply(airByMonth, function(x){colMeans(x, na.rm=T)},
FUN.VALUE = seq(0.1,6) ) #整型1改为 0.1就不报错了
# 报错:返回值长度不对
> vapply(airByMonth, function(x){colMeans(x, na.rm=T)},
+ FUN.VALUE = seq(0.1,2) )
Error in vapply(airByMonth, function(x) { : values must be length 2,
but FUN(X[[1]]) result is length 6
# 长度对,类型只要有一个double就不报错了
vapply(airByMonth, function(x){colMeans(x, na.rm=T)},
FUN.VALUE = c(1,2,3,4,5,6.01) )
# 额外的好处: 指定返回值行名为a,b,c...
vapply(airByMonth, function(x){colMeans(x, na.rm=T)},
FUN.VALUE = c('a'=1, 'b'=1, 'c'=1, 'd'=1, 'e'=1, 'f'=1) )
# 把返回值的行名精简为前3个字母
rn=substr(colnames(airquality),1,3); rn
fv=seq(0.9,6);fv
names(fv)=rn;fv
# Ozo Sol Win Tem Mon Day
# 0.9 1.9 2.9 3.9 4.9 5.9
vapply(airByMonth, function(x){colMeans(x, na.rm=T)},
FUN.VALUE = fv )
# 5 6 7 8 9
# Ozo 23.61538 29.44444 59.115385 59.961538 31.44828
# Sol 181.29630 190.16667 216.483871 171.857143 167.43333
# Win 11.62258 10.26667 8.941935 8.793548 10.18000
# Tem 65.54839 79.10000 83.903226 83.967742 76.90000
# Mon 5.00000 6.00000 7.000000 8.000000 9.00000
# Day 16.00000 15.50000 16.000000 16.000000 15.50000
如果想让返回值是某个类型,vapply 更安全,是因为它比 sapply多了一步返回值校验。
a=vapply(NULL, is.factor, FUN.VALUE=logical(1));a #logical(0)
b=sapply(NULL, is.factor);b #list()
is.logical(a) #TRUE
is.logical(b) #FALSE
# https://stackoverflow.com/questions/12339650/why-is-vapply-safer-than-sapply
另一个检查返回值的例子,输入一个字符串,输出一个字符串。
例3:对16进制的颜色倒转#后的6位
hexadecimal=c("#FF0000", "#FFFF00")
vapply(
X = toupper(x = hexadecimal), #先变大写字母
FUN = function(hex) {
hex=substring(hex,2)
hex=rev(strsplit(hex, split="")[[1]] )
hex=paste(hex, collapse = "")
return( paste0("#", hex) )
},
FUN.VALUE = character(length = 1L), #返回值是字符串,长度为1
USE.NAMES =FALSE #不使用名字
)
# [1] "#0000FF" "#00FFFF"
mapply(FUN, …) #m stands for multi-variant apply.
由于mapply是可以接收多个参数的,所以我们在做数据操作的时候,就不需要把数据先合并为data.frame了,
直接一次操作就能计算出结果了。
#例1
mapply(sum, list(a=1,b=2,c=3), list(a=10,b=20,d=30))
#a b c
#11 22 33
#例2
mapply(function(x,y) x^y, c(-1:-5), c(1:5))
#[1] -1 4 -27 256 -3125
# 例3: 求每一列的均值,数据框也是列向量
mapply(sum, iris[,1:4])
#Sepal.Length Sepal.Width Petal.Length Petal.Width
# 876.5 458.6 563.7 179.9
# 结果和 colSums(iris[,1:4]) 相同。
# 例4:mapply对每一个位置做运算,及时列名不一致。返回时使用第一个参数的名字
mapply(
function(u,v){
(u+v)*2
},
c(A=20,B=1,C=40),
c(J=430,K=50,L=10)
)
# A B C
# 900 102 100
# 如果某个向量短,则会循环使用其中的元素
mapply(
function(u,v){
(u+v)*2
},
c(A=20,B=1,C=40),
c(J=430,K=50)
)
# A B C
#900 102 940
并警告 Warning message:
In mapply(function(u, v) { :
longer argument not a multiple of length of shorter
# 例10:输出重复次数的数字,越小重复越多
mapply(rep,1:4,4:1)
do.call(c, mapply(rep,1:4,4:1))
#[1] 1 1 1 1 2 2 2 3 3 4
tapply 用于分组的循环计算,通过INDEX参数可以把数据集X进行分组,相当于group by的操作。只能接收一维 vector 输入。
函数定义:tapply(X, INDEX, FUN = NULL, ..., simplify = TRUE)
参数列表:
X: 向量
INDEX: 用于分组的索引
FUN: 自定义的调用函数
...: optional arguments to FUN: the Note section. 接收多个数据
simplify : 是否数组化,当值array时,输出结果按数组进行分组
#tapply(a,b,c)
# a是一个一维数据,如 1,2,3,4,5,6
# b是和a等长度的一维数据,如 a,a,b,c,b,c
# c是执行函数,如求和 sum,结果是a的求和值为 1+2 = 3, b的求和值为 3+5=8,c的求和值为4+6=10
# 例1: 对不同位置求和
tapply(c(1,2,3,4,5,6), c('a','a','b','c','b','c'), sum)
# a b c
# 3 8 10
#例2: 计算不同品种的鸢尾花花瓣长度均值
# 通过iris$Species品种进行分组
tapply(iris$Petal.Length,iris$Species,mean)
# setosa versicolor virginica
# 1.462 4.260 5.552
# 例3: 传入更多参数
#由于 tapply 只接收一个向量参考,通过’…’可以把再传给你FUN其他的参数,那么我们想去y向量也进行求和,
#把y作为tapply的第4个参数进行计算。
y=1:150
tapply(iris$Petal.Length,iris$Species,sum)
#setosa versicolor virginica
# 73.1 213.0 277.6
tapply(iris$Petal.Length,iris$Species,sum, y)
#setosa versicolor virginica
# 11398.1 11538.0 11602.6
sum(y) #[1] 11325
## 警告:
#得到的结果并不符合我们的预期,结果不是把X和Y对应的Indx分组后求和,而是得到了其他的结果。
#第4个参数y传入sum时,并不是按照循环一个一个传进去的,而是每次传了完整的向量数据,
#那么再执行sum时sum(y)=11325,所以 73.1 + 11325=11398.1
#那么,我们在使用’…’去传入其他的参数的时候,一定要看清楚传递过程的描述,才不会出现的算法上的错误。
tapply(iris$Petal.Length,iris$Species,sum) + tapply(y, iris$Species,sum)
#setosa versicolor virginica
#1348.1 3988.0 6552.6
# 实例
head(mtcars)
# 1维:gear Number of forward gears
tapply(mtcars$mpg, mtcars$gear, mean) #参数1 数据,参数2 分组, 参数3 处理函数
# 3 4 5
# 16.10667 24.53333 21.38000
# 2维:cyl Number of cylinders
tapply(mtcars$mpg, list(mtcars$gear, mtcars$cyl), mean)
# 4 6 8
#3 21.500 19.75 15.05
#4 26.925 19.75 NA
#5 28.200 19.70 15.40
# 怎么去掉结果中的 NA ?去掉原数据中的NA,或者没这个交叉数据数据的设置默认值.
tapply(mtcars$mpg, list(mtcars$gear, mtcars$cyl), mean, na.rm=TRUE, default = -1)
# 4 6 8
#3 21.500 19.75 15.05
#4 26.925 19.75 -1
#5 28.200 19.70 15.40
by 可以当成dataframe上的 tapply 。 indices 应当和dataframe每列的长度相同。
返回值是 by 类型的object。若simplify=FALSE,本质上是个list。
# 例1: 数据框按奇偶行分组并统计
a=data.frame(
'x1'=c(1,2,3,4),
'x2'=c(10,20,30,40)
)
a
# x1 x2
#1 1 10
#2 2 20
#3 3 30
#4 4 40
ind=a$x1 %% 2; ind #[1] 1 0 1 0 按奇偶行分组
tapply(a$x2,ind,sum)
#0 1
#60 40
> by(a,ind,sum)
> by(a,ind,sum,simplify=T) #没看到T和F的差别
ind: 0
[1] 66
------------------------------------------------------------------------
ind: 1
[1] 44
# 按行求和
> by(a,ind,rowSums)
> by(a,ind,function(x){ apply(x, 1, sum) }, simplify = T)
ind: 0
2 4
22 44
------------------------------------------------------------------------
ind: 1
1 3
11 33
# 按列求和
> by(a,ind,colSums)
> by(a,ind,function(x){ apply(x, 2, sum) }, simplify = T)
ind: 0
x1 x2
6 60
------------------------------------------------------------------------
ind: 1
x1 x2
4 40
> by(a,ind,colMeans) #ind行分类,colMeans按列求平均
> by(a,ind,function(x){ apply(x, 2, mean) }, simplify = T)
> by(a,ind,rowMeans) #ind行分类,rowMeans按行row求平均
> by(a,ind,function(x){ apply(x, 1, mean) }, simplify = T)
by() 可以代替 aggregate() 做分组统计,而且支持多个返回值。
例2:分组统计可使用 aggregate() 或 sapply()组合。
如果 by=list(iris$Species) 中没有添加 Species= ,则第一列列名是 Group.1。
#例2: 鸢尾花按亚类分组,统计组内各指标的均值
> aggregate(iris[,1:4], by=list( Species2 = iris$Species ), FUN=mean)
输出:
Species2 Sepal.Length Sepal.Width Petal.Length Petal.Width
1 setosa 5.006 3.428 1.462 0.246
2 versicolor 5.936 2.770 4.260 1.326
3 virginica 6.588 2.974 5.552 2.026
# 更紧凑的结果: 带 rownames
> sapply(split(iris[,1:4], iris$Species), function(x){
apply(x, 2, mean)
})
输出:
setosa versicolor virginica
Sepal.Length 5.006 5.936 6.588
Sepal.Width 3.428 2.770 2.974
Petal.Length 1.462 4.260 5.552
Petal.Width 0.246 1.326 2.026
aggregate 只能调用单返回值函数,无法一次返回若干统计量。
例3: 想多个返回值,使用 by() 函数: by(data, INDICES, FUN)。
# 例3: 鸢尾花按亚类分组,统计组内各指标的中位数、均值、方差、变异系数、峰度等。
by(iris[,1:4], iris$Species, function(x2){
sapply(x2, function(x){
n=length(x)
m=mean(x)
s=sd(x)
cv=s/m
return( c(n=n, mean=m, sd=s, cv=cv))
})
})
封装成函数
# 函数化
mystat=function(x2){
sapply(x2, function(x){
n=length(x)
md=median(x)
m=mean(x)
s=sd(x)
cv=s/m
skew=sum( (x-m)^3/s^3) /n
kurt=sum( (x-m)^4/s^4) /n -3
return( c(n=n, median=md, mean=m, stdev=s, cv=cv, skew=skew, kurtosis=kurt))
})
}
by(iris[,1:4], iris$Species, mystat)
输出:
iris$Species: setosa
Sepal.Length Sepal.Width Petal.Length Petal.Width
n 50.00000000 50.00000000 50.0000000 50.0000000
median 5.00000000 3.40000000 1.5000000 0.2000000
mean 5.00600000 3.42800000 1.4620000 0.2460000
stdev 0.35248969 0.37906437 0.1736640 0.1053856
cv 0.07041344 0.11057887 0.1187852 0.4283967
skew 0.11297784 0.03872946 0.1000954 1.1796328
kurtosis -0.45087239 0.59595073 0.6539303 1.2587179
------------------------------------------------------------------------
iris$Species: versicolor
Sepal.Length Sepal.Width Petal.Length Petal.Width
n 50.00000000 50.0000000 50.0000000 50.00000000
median 5.90000000 2.8000000 4.3500000 1.30000000
mean 5.93600000 2.7700000 4.2600000 1.32600000
stdev 0.51617115 0.3137983 0.4699110 0.19775268
cv 0.08695606 0.1132846 0.1103077 0.14913475
skew 0.09913926 -0.3413644 -0.5706024 -0.02933377
kurtosis -0.69391378 -0.5493203 -0.1902555 -0.58731442
------------------------------------------------------------------------
iris$Species: virginica
Sepal.Length Sepal.Width Petal.Length Petal.Width
n 50.00000000 50.0000000 50.00000000 50.0000000
median 6.50000000 3.0000000 5.55000000 2.0000000
mean 6.58800000 2.9740000 5.55200000 2.0260000
stdev 0.63587959 0.3224966 0.55189470 0.2746501
cv 0.09652089 0.1084387 0.09940466 0.1355627
skew 0.11102862 0.3442849 0.51691747 -0.1218119
kurtosis -0.20325972 0.3803832 -0.36511606 -0.7539586
rapply是一个递归版本的lapply,它只处理list类型数据,对list的每个元素进行递归遍历,如果list包括子元素则继续遍历。
#rapply(object, f, classes = "ANY", deflt = NULL,
# how = c("unlist", "replace", "list"), ...)
#Arguments 参数列表
# classes : 匹配类型, ANY为所有类型
# deflt: 非匹配类型的默认值
# how: 3种操作方式,
# 当为replace时,则用调用f后的结果替换原list中原来的元素;
# 当为list时,新建一个list,类型匹配调用f函数,不匹配赋值为deflt;
# 当为unlist时,会执行一次unlist(recursive = TRUE)的操作
X1 = list(
list(
a = pi,
b = list(c = 2)
),
d = "a test")
X1
str(X1)
rapply(X1, function(x) x, how = "replace")
rapply(X1, sqrt, classes = "numeric", how = "replace")
rapply(X1, nchar, classes = "character",
deflt = as.integer(NA), how = "list")
rapply(X1, nchar, classes = "character",
deflt = as.integer(NA), how = "unlist")
rapply(X1, log, classes = "numeric", how = "replace", base = 10)
rapply(X1, log, classes = "numeric", how = "list", base = 10)
作用就是基于by指定的变量做分组,计算FUN分别统计每个组的结果。
例子在本页中查找: ctrl+F 输入本函数名
sweep(x, MARGIN, STATS, FUN = "-", check.margin = TRUE, ...)
例: 数据框每列乘以一个不同的数字。
> t1=iris[1:3, 1:4]
> t1
Sepal.Length Sepal.Width Petal.Length Petal.Width
1 5.1 3.5 1.4 0.2
2 4.9 3.0 1.4 0.2
3 4.7 3.2 1.3 0.2
这四列分别乘以10, -1, 2, -10:
> sweep(t1, MARGIN = 2, STATS = c(10, -1, 2, -10), FUN = "*")
Sepal.Length Sepal.Width Petal.Length Petal.Width
1 51 -3.5 2.8 -2
2 49 -3.0 2.8 -2
3 47 -3.2 2.6 -2